# 第7章 正则表达式
# 贪婪性匹配和非贪婪性匹配
紧跟在任何量词 *、 +、? 或 {} 的后面,将会使量词变为非贪婪(匹配尽量少的字符),和缺省使用的贪婪模式(匹配尽可能多的字符)正好相反。例如,对 "123abc" 使用 /\d+/ 将会匹配 "123",而使用 /\d+?/ 则只会匹配到 "1"。

如果只有一个量词,表示趋向于进行贪婪性匹配,即匹配尽可能多的副本直至达到上限。
如果这个量词附加一个后缀?,则表示趋向于非贪婪性匹配,即只匹配必要的副本就好。
一般情况下最好坚持使用贪婪性匹配。
# 分组

# 捕获型
一个捕获型分组是一个被包围在括号中的正则表达式分支
# 非捕获型
?:前缀,非捕获型分组仅做简单的匹配,并不会捕获所匹配的文本。
(?:x)匹配 'x' 但是不记住匹配项。这种括号叫作非捕获括号
如果表达式是 /foo{1,2}/,{1,2} 将只应用于 'foo' 的最后一个字符 'o'。如果使用非捕获括号,则 {1,2} 会应用于整个 'foo' 单词
var re = /quick\s(brown).+?(?:jumps)/gi;
var results = re.exec('The Quick Brown Fox Jumps Over The Lazy Dog');
console.log(results)//["Quick Brown Fox Jumps", "Brown", index: 4, input: "The Quick Brown Fox Jumps Over The Lazy Dog", groups: undefined]
2
3
# 正则表达式的方法
正则表达式的方法有:regexp.exec、regexp.test、string.match、string.replace、string.search、string.split
- \d等同于[0-9]
- \w等同于[0-9a-z_A-Z]
search会忽略g标识,且没有position参数
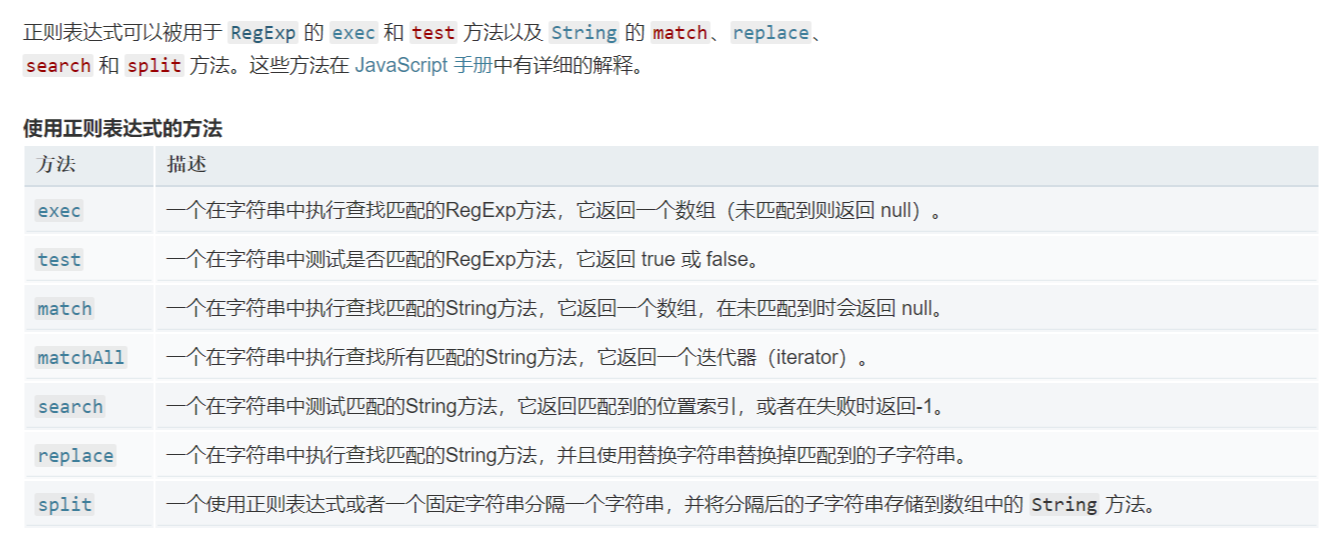
# replace
预定义的 RegExp 对象的属性($1,... ,$9)来访问匹配。
# regexObj.exec(str)
如果匹配成功,exec() 方法返回一个数组,并更新正则表达式对象的属性。返回的数组将完全匹配成功的文本作为第一项,将正则括号里匹配成功的作为数组填充到后面。
如果匹配失败,exec() 方法返回 null。
如果exec中带有g标识。查找不是从这个字符串的起始位置开始,而是从refexp.lastIndex(初始值为0)位置开始。如果匹配成功那么lastIndex将被设置为该匹配后的第一个字符位置。不成功的匹配会重置lastIndex为0。
match无/g、matchAll、exec、split可以像以下方式进行捕获(先返回完全匹配成功的文本做为数组第一项,然后将捕获的填充到数组后面)。
matchAll返回一个迭代器,有无/g都返回捕获的内容,match中/g全局匹配不返回捕获组中的内容。
var re = /quick\s(brown).+?(?:jumps)/gi;
var results = re.exec('The Quick Brown Fox Jumps Over The Lazy Dog');
console.log(results)//["Quick Brown Fox Jumps", "Brown", index: 4, input: "The Quick Brown Fox Jumps Over The Lazy Dog", groups: undefined]
2
3
# str.match(regexp)
如果使用g标志,则将返回与完整正则表达式匹配的所有结果(Array),但不会返回捕获组,或者未匹配 null。
如果未使用g标志,则仅返回第一个完整匹配及其相关的捕获组(Array)。 在这种情况下,返回的项目将具有如下所述的其他属性,或者未匹配 null。
var s='The Quick Brown Fox Jumps Over The Lazy Dog'.match(/quick\s(brown).+?(jumps)/ig);
console.log(s)//["Quick Brown Fox Jumps"]
var s='The Quick Brown Fox Jumps Over The Lazy Dog'.match(/quick\s(brown).+?(jumps)/i);
console.log(s)//["Quick Brown Fox Jumps", "Brown", "Jumps", index: 4, input: "The Quick Brown Fox Jumps Over The Lazy Dog", groups: undefined]
2
3
4
# str.matchAll(regexp)
一个迭代器(不可重用,结果耗尽需要再次调用方法,获取一个新的迭代器)。
matchAll 的另外一个亮点是更好地获取分组捕获。因为当使用match()和/g标志方式获取匹配信息时,分组捕获会被忽略。
var regexp = /t(e)(st(\d?))/g;
var str = 'test1test2';
str.match(regexp);
// Array ['test1', 'test2']
let array = [...str.matchAll(regexp)];
console.log(array);
array[0];
// ['test1', 'e', 'st1', '1', index: 0, input: 'test1test2', length: 4]
array[1];
// ['test2', 'e', 'st2', '2', index: 5, input: 'test1test2', length: 4]
var regexp = /t(e)(st(\d?))/;
let arrays = [...str.matchAll(regexp)];
console.log(arrays)//[['test1', 'e', 'st1', '1', index: 0, input: 'test1test2', length: 4]]
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# str.split([separator[, limit]])
如果 separator 包含捕获括号(capturing parentheses),则其匹配结果将会包含在返回的数组中。
var myString = "Hello 1 word. Sentence number 2.";
var splits = myString.split(/(\d)/);
console.log(splits);//[ "Hello ", "1", " word. Sentence number ", "2", "." ]
2
3
# str.replace(regexp|substr, newSubStr|function)
replace() 方法返回一个由替换值(replacement)替换一些或所有匹配的模式(pattern)后的新字符串。没有/g只替换第一个匹配到的值,数组没有replace。
function replace(match, p1, p2, p3, offset, string) {
// match匹配到的字符串
return [p1, p2, p3].join(' - ');
}
var newString = 'abc12345#$*%'.replace(/([^\d]*)(\d*)([^\w]*)/, replacer);
console.log(newString); // abc - 12345 - #$*%
var rg = /apples/gi;
var str = "Apples are round, and apples are juicy.";
var newstr = str.replace(re, "oranges");
console.log(newstr);
// oranges are round, and oranges are juicy.
var re = /apples/i;
var newsstr = str.replace(rg, "oranges");
console.log(newsstr);
//oranges are round, and apples are juicy.
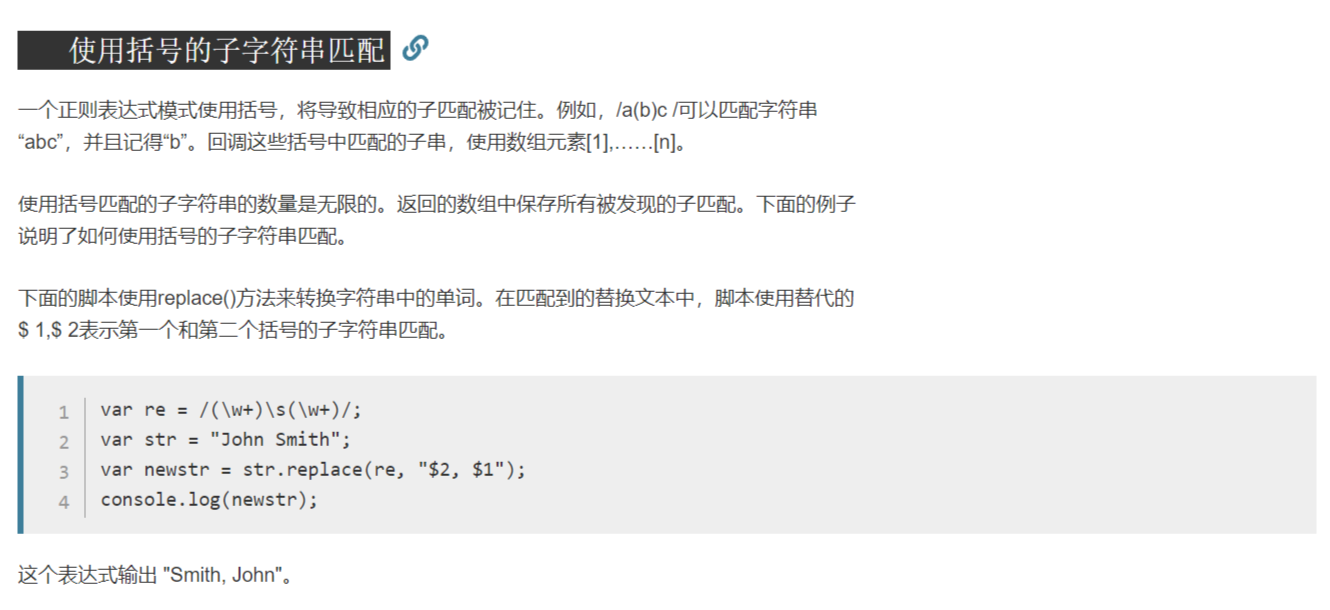
var re = /(\w+)\s(\w+)/;
var str = "John Smith";
var newstr = str.replace(re, "$2, $1");
// Smith, John
console.log(newstr);
//$$代表替换对象为$
//$&代表整个匹配的文本
//$number代表分组捕获的文本
//$`代表匹配之前的文本
//$'代表匹配之后的文本
'abc'.repeat()//""
'abc'.repeat(2)//"abcabc"
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
# 转义
\ / [ ] ( ) { } ? + * | . ^ $
要匹配到上面字符需要用\前缀来进行转义。如果你拿捏不准,可以给任何特殊字符都添加\来使其字面化。
注意\前缀不能使字母或数字字面化
var r1=/\2/g
var r2=/2/g
'213'.match(r1)//null
'213'.match(r2)//['2']
var s=/\_/g
var t=/_/g
'213__'.match(s)//['_','_']
'213__'.match(t)//['_','_']
2
3
4
5
6
7
8
9